以下有任何問題,歡迎直接私訊我的IG
點我私訊
在資料分析過程中,異常值和重複值可能會影響我們的分析結果。因此,在進行資料分析之前,發現並處理這些異常情況是非常重要的。今天我們將學習如何檢測和處理資料中的異常值與重複值。
首先,請在同一個資料夾中開啟新的 Google Colab 筆記本,名稱為 iris_abnormal。在第一段程式碼中,請輸入以下內容: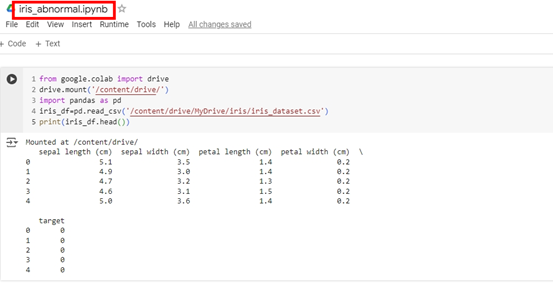
from google.colab import drive
drive.mount('/content/drive/')
import pandas as pd
# 讀取 CSV 檔案
iris_df = pd.read_csv('/content/drive/MyDrive/iris/iris_dataset.csv')
print(iris_df.head())
重複值是指資料集中出現兩次或更多次的完全相同的數據行。這些重複的數據可能會導致分析結果出現偏差,因此需要在分析之前進行處理。我們可以使用 duplicated() 函數來檢測重複值,並使用 drop_duplicates() 來刪除它們:
# 檢查是否有重複的資料行
duplicates = iris_df.duplicated()
print("重複資料行:")
print(iris_df[duplicates])
# 刪除重複的資料行
iris_no_duplicates = iris_df.drop_duplicates()
print("刪除重複值後的資料集:")
print(iris_no_duplicates.head())
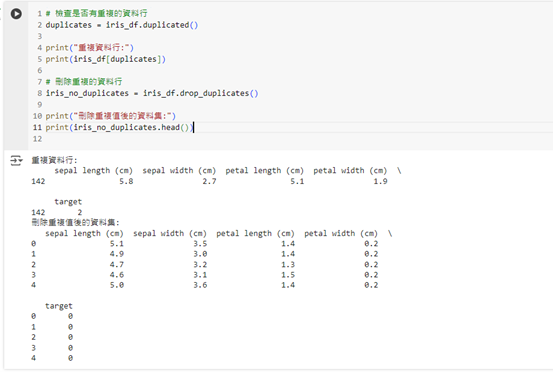
這段程式碼將檢查資料集中的重複行,並顯示所有重複的資料行。接著,它會刪除重複的資料行,並顯示刪除重複值後的資料集。
異常值是指遠離其他資料點的極端值,這些異常值可能是由於資料輸入錯誤或其他原因造成的。異常值的處理方式有時會根據具體情況選擇刪除或保留。檢測異常值的方法包括使用統計測量(如四分位距)或視覺化工具(如箱型圖)來檢查資料的分佈情況。
我們可以使用 describe() 函數來查看資料的分佈,從中發現可能的異常值:
# 查看資料的統計描述
print(iris_df.describe())
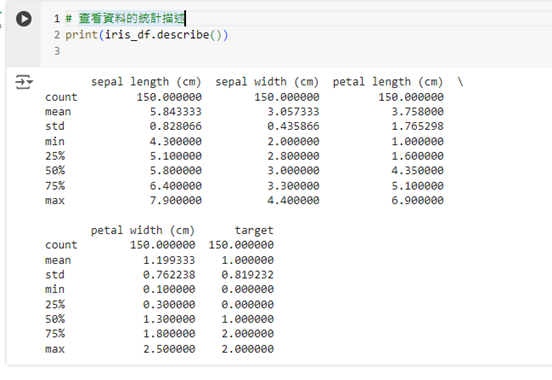
此時,我們可以觀察數據中的最小值和最大值,從而檢查是否有異常值出現。如果資料的最小值或最大值過於偏離中位數或四分位距,這些值可能就是異常值。
一旦我們發現異常值,可以選擇將其刪除或進行其他處理(如用中位數或平均值替換)。以下是刪除異常值的範例:
# 使用 IQR(四分位距)檢測並刪除異常值
Q1 = iris_df['sepal length (cm)'].quantile(0.25)
Q3 = iris_df['sepal length (cm)'].quantile(0.75)
IQR = Q3 - Q1
# 定義異常值的範圍(通常為 1.5 倍 IQR 之外的值)
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 篩選出非異常值
iris_no_outliers = iris_df[(iris_df['sepal length (cm)'] >= lower_bound) & (iris_df['sepal length (cm)'] <= upper_bound)]
print("刪除異常值後的資料集:")
print(iris_no_outliers.head())
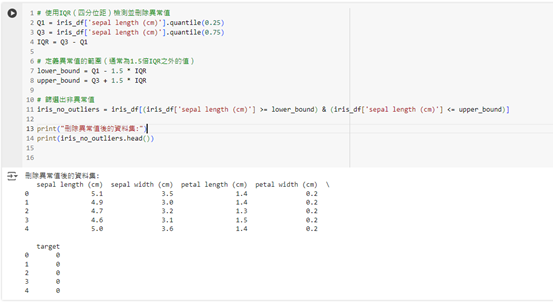
這段程式碼會使用四分位距(IQR)來檢測並刪除 sepal length (cm) 中的異常值。這種方法適合資料分佈較為對稱或呈正態分佈的情況。
今天我們學習了如何處理資料中的重複值與異常值,包括:
duplicated() 和 drop_duplicates() 檢查並刪除重複值。處理重複值和異常值有助於提高資料的準確性和分析的可信度。下一步,我們將進一步探討資料的切片和篩選技術。


 iThome鐵人賽
iThome鐵人賽